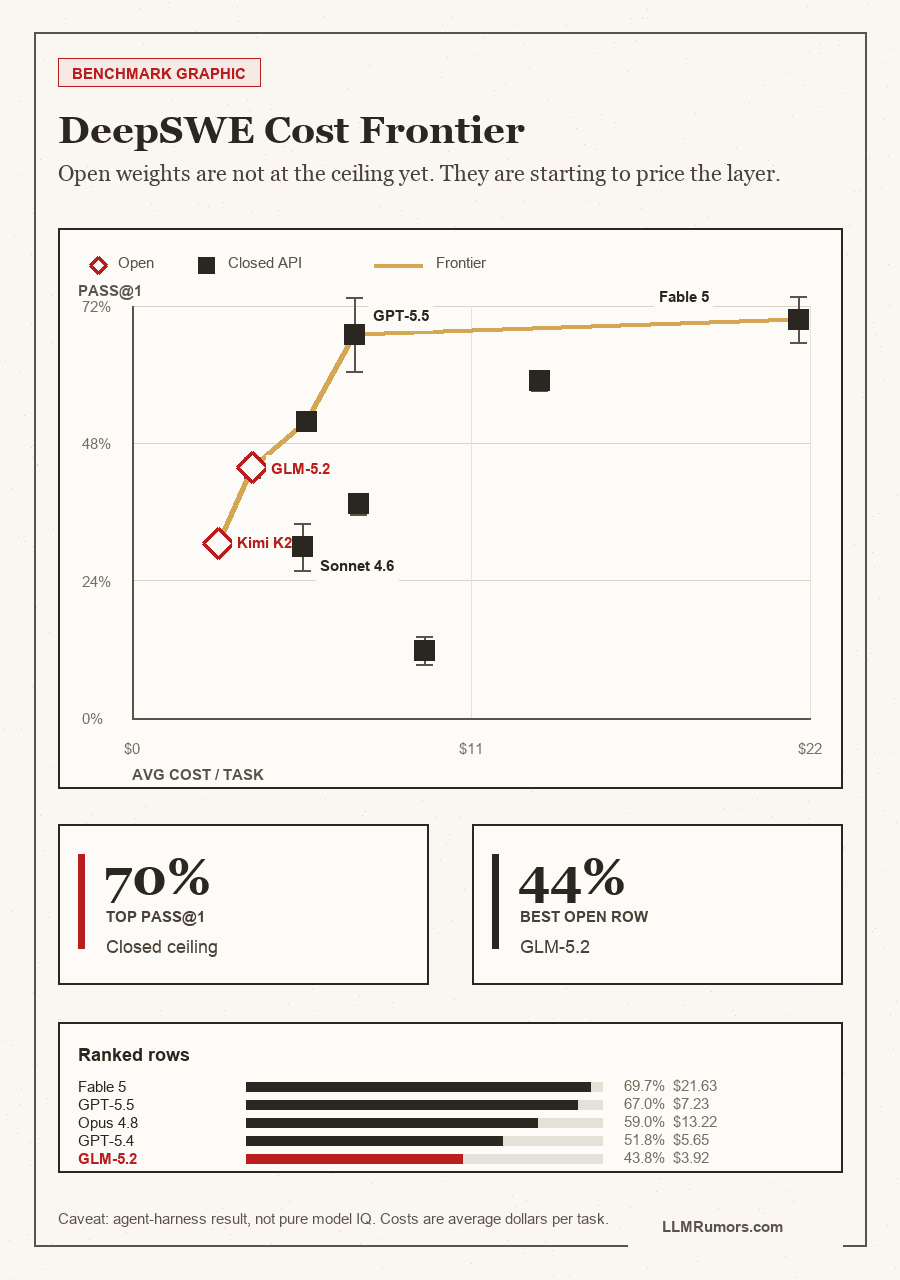
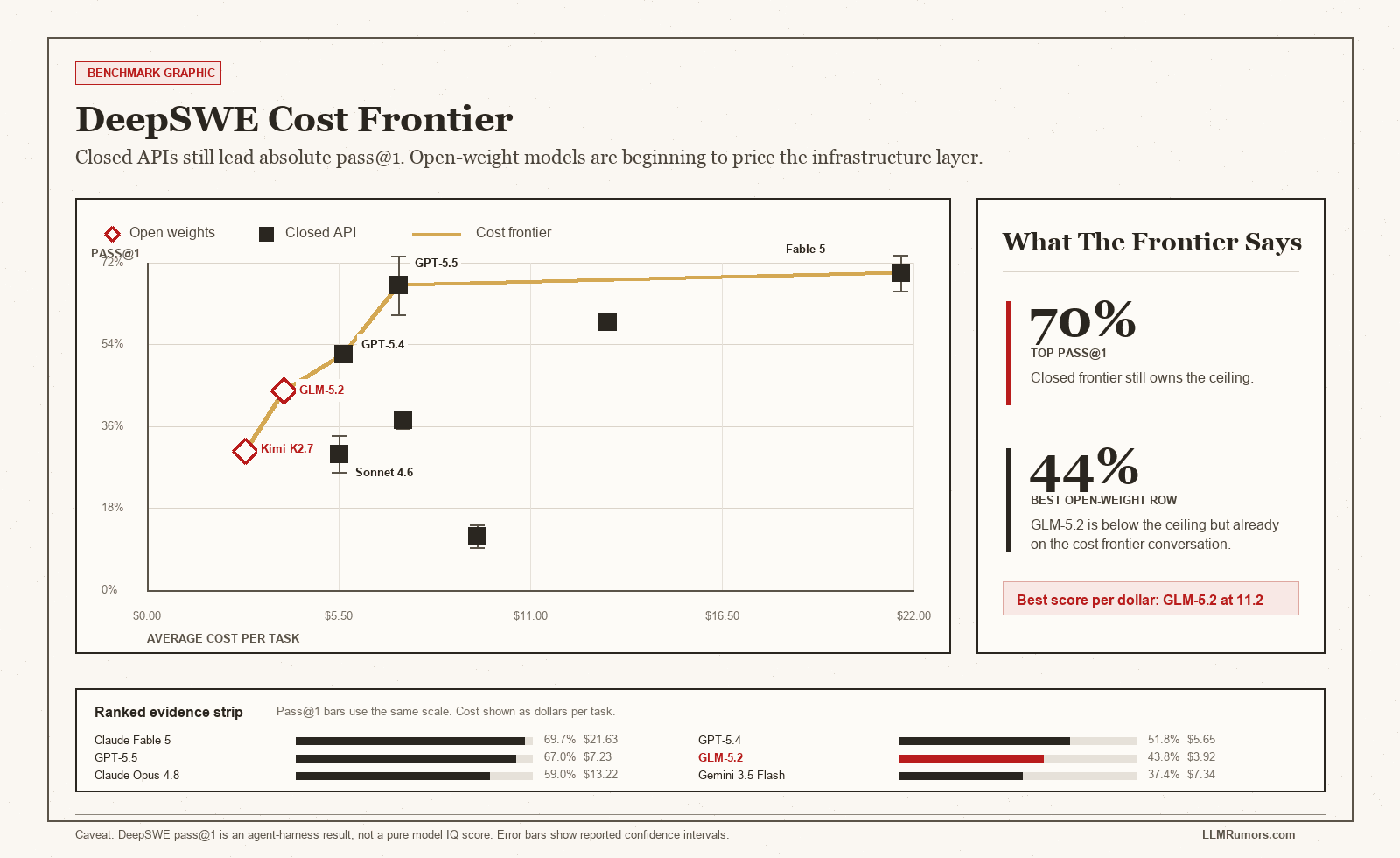
TL;DR: Open-source AI looks, at first, like a benchmark catch-up story. That is not the real story. DeepSWE's live v1.1 snapshot has closed models leading at 69.7 percent pass@1, but open-weight GLM-5.2 already posts 43.8 percent at $3.92 per task and Kimi K2.7 Code posts 30.5 percent at $2.82.[1] The uncomfortable truth is that open models do not need to beat every closed model this quarter. They need to become the infrastructure layer, the way Linux, Kubernetes, Apache, Postgres, and Android became unavoidable despite starting from weaker positions.[8][9][11]
Open-weight foundation models look like a scoreboard problem. Closed labs have the best models, the best product polish, the best inference farms, and the best enterprise sales machines. Open models have files on Hugging Face, noisy licenses, uneven serving stacks, and too many people pretending that a single benchmark row settles the argument.
That is not the real story.
The real story is whether intelligence becomes a rented metered service or a shared infrastructure primitive. Linux did not win because it was always prettier than proprietary Unix. Kubernetes did not win because YAML was elegant. Open infrastructure wins when the market needs portability, auditability, customization, pricing pressure, and an exit door more than it needs the incumbent's perfect product packaging.
Why This Matters Now
AI agents are moving from demo surfaces into production workflows. Once a model sits inside code review, customer support, internal search, compliance automation, deployment pipelines, data cleaning, and local device inference, buyers stop asking only which model is smartest. They start asking who controls the layer their business now depends on.
The Open Infrastructure Case
The debate is not only model quality. It is infrastructure control, cost pressure, and historical compounding.
DeepSWE v1.1 evaluates long-horizon coding agents on original tasks across active open-source repositories.
GLM-5.2 posts 43.8 percent pass@1 at $3.92 average cost in the live v1.1 data.
Kimi K2.7 Code is below every closed model in the DeepSWE best-view cost column.
Harvard Business School estimated the demand-side value of widely used open-source software at $8.8 trillion.
CNCF says 82 percent of container users now run Kubernetes in production.
The 2026 State of Open Source Report says 55 percent of respondents cite avoiding vendor lock-in as a driver.
The Real Story: Benchmarks Are Not The Battleground
Let's be clear: closed frontier models still lead. Anyone pretending otherwise is doing advocacy, not analysis. In the current DeepSWE v1.1 live data, Claude Fable 5 sits near 69.7 percent pass@1 and GPT-5.5 sits at 67.0 percent.[1] That matters. If your workflow needs the strongest long-horizon coding agent today and cost is secondary, the closed frontier still has the obvious answer.
But infrastructure markets do not resolve at the top row of a leaderboard.
The real story isn't that open models are already better. The real story is that open models have entered the same measurement frame. GLM-5.2 is in the DeepSWE live table at 43.8 percent pass@1 with $3.92 average cost. Kimi K2.7 Code sits at 30.5 percent with $2.82 average cost.[1] That is not frontier supremacy. It is price discovery.
Once open models become good enough for repeated infrastructure calls, they do not need to win every premium task. They win routing, summarization, codebase search, private fine-tunes, local review, long-tail enterprise workflows, and all the places where the best answer is not worth a closed API dependency.
The Open-Weight Roster
This panel compares open and open-weight models on published model-card facts. Scores are not merged into one ranking unless they use the same benchmark and harness.
GLM-5.2
The open model most clearly aimed at long-horizon agent infrastructure. Its pitch is not local hobby usage. It is inspectable enterprise-grade reasoning with a real deployment stack.
Kimi K2.7 Code
A coding-specific open-weight model built for agent loops, not generic chat prestige. Its DeepSWE cost row is the pressure point.
Qwen3-235B-A22B Thinking
The permissive-license China stack matters because enterprises can route around a single Western API market.
Mistral Large 3
The European open-weight counterweight. The strategic asset is not just the model. It is sovereign deployment.
Gemma 4
Gemma is the edge and developer ecosystem play. It makes the open stack available on real devices, not only cloud clusters.
DiffusionGemma
The architecture wildcard. It is less about top reasoning and more about owning the fast subagent layer.
The open-model argument has a public-market layer too. These are the listed companies or public proxies tied to the model families and open-source infrastructure precedents discussed in the article.
The Linux Pattern: Good Enough Becomes Everywhere
The lazy version of the Linux analogy is that open source always wins because free things are cheaper. That misses the mechanism.
Linux won because it became the neutral layer that every vendor could build on without surrendering to another vendor's roadmap. Hardware makers could support it. Cloud providers could standardize on it. Enterprises could audit it. Startups could ship on it. Researchers could modify it. Consultants could sell around it. Competitors could collaborate on the bottom of the stack and fight higher up.
IBM is the clean proof. IBM did not crush Linux. IBM became an early supporter of Linux, spent decades building with Red Hat, and then agreed to buy Red Hat for $34 billion in 2018 because open hybrid cloud had become the enterprise control plane.[12] Red Hat's release explicitly framed Linux, containers, Kubernetes, and multi-cloud management as shared technologies that unlocked portability across clouds.[12]
IBM did not beat Linux. IBM bought the enterprise distribution layer around it.
What's often overlooked is that Linux did not stop at servers. By 2017, Linux powered every one of the world's 500 fastest supercomputers, according to the Linux Foundation's summary of the TOP500 list.[13] Kubernetes followed the same pattern in cloud orchestration. CNCF now says 82 percent of container users run Kubernetes in production and 66 percent of organizations hosting generative AI models use Kubernetes to manage some or all inference workloads.[11]
That is the playbook. First the incumbent says open infrastructure is not polished enough. Then developers use it anyway. Then enterprises use it to avoid lock-in. Then vendors wrap services around it. Then the incumbent has to support it because the market already moved.
The Open-Source Advantage: Control Beats Raw IQ In The Infrastructure Layer
Open models do not have to replace frontier chatbots to matter. They have to take the calls that turn into infrastructure.
A production AI system is not one glamorous prompt. It is retrieval. It is classification. It is routing. It is extraction. It is codebase search. It is diff explanation. It is log summarization. It is data transformation. It is agent memory compaction. It is thousands of repeatable calls where policy opacity, rate limits, model retirement, and per-token rent become a business liability.
That is where open weights become strategic. If a startup can run a good-enough model in its own cluster, it gets margin leverage. If an enterprise can fine-tune a model on private workflows, it gets auditability. If a government can deploy a model without routing sensitive data through a foreign API, it gets sovereignty. If a researcher can inspect and reproduce behavior, it gets science instead of faith.
Who Benefits When Models Become Open Infrastructure
The infrastructure argument is different for each buyer, but the direction is the same: less dependency on a single closed model provider.
Startups
Open models give startups margin control and negotiating leverage against API vendors.
Enterprises
Open weights make compliance, audit, retention, and custom deployment easier to reason about.
Researchers
Open models preserve reproducibility in a field drifting toward closed black-box endpoints.
Cloud providers
Open models let infrastructure vendors compete above the model layer.
Here is the genius. Closed labs sell the finished product. Open ecosystems sell the ability to build the rest of the market.
The Closed-Lab Problem: APIs Are Convenient Until They Become Critical
Closed APIs are better than open weights at many things. They remove deployment burden. They hide serving complexity. They provide fast upgrades. They package safety, billing, model selection, and enterprise contracts into something procurement can understand.
That convenience is real. It is also the trap.
When an API is a feature, renting it is rational. When an API becomes infrastructure, renting it blindly becomes dangerous. The provider can change pricing. The provider can deprecate models. The provider can route requests differently. The provider can change safety behavior. The provider can add hidden transformations. The provider can decide which categories of research are acceptable. The user may discover the boundary only after a failed workflow, a changed answer, or an unexpected bill.
That is why this matters beyond ideology. The 2026 State of Open Source Report says 55 percent of respondents cite avoiding vendor lock-in as a driver of open source adoption, up 68 percent year over year.[10] That is not a hobbyist emotion. That is enterprise risk management.
Closed API Versus Open Weights
| Feature | Closed API | Open Weights |
|---|---|---|
| Default advantage | Best frontier capability, managed serving, simple procurement | Control, portability, auditability, custom deployment |
| Main weakness | Provider dependency, opaque behavior, price and policy exposure | Deployment burden, uneven quality, security ownership |
| Where it wins | Premium reasoning, consumer assistant polish, hard agent tasks | High-volume internal calls, private workflows, local agents, regulated deployment |
| Economic model | Metered intelligence rent | Infrastructure plus services around a shared primitive |
| Strategic question | Can the provider keep the frontier far enough ahead? | Can the ecosystem compound faster than the gap matters? |
Open weights have their own problems. Let's be clear about that too. License diligence matters. Safety ownership shifts to the deployer. Fine-tuning can create new risks. Serving a trillion-parameter model is not the same thing as downloading a file. Open-source AI is not magic.
But neither was Linux.
The Roster: Open Models Are Becoming A Stack
The strongest sign that open models are having a Linux moment is not one heroic model. It is the shape of the ecosystem.
GLM-5.2 is a long-context, MIT-licensed model with a 1 million-token context window and local serving support across SGLang, vLLM, Transformers, KTransformers, and Unsloth.[3] Kimi K2.7 Code is a coding-focused open-weight model with 1T total parameters, 32B active parameters, 256K context, and a Modified MIT license.[4] Qwen3-235B-A22B Thinking is Apache 2.0, has 235B total parameters with 22B active, and reports 74.1 on LiveCodeBench v6 in its model card.[5]
Mistral Large 3 pushes the European enterprise angle with Apache 2.0 weights, 675B total parameters, 41B active parameters, and a deployability pitch around NVFP4 on one 8x H100 or A100 node.[6] Gemma 4 and DiffusionGemma push the local, multimodal, and fast-generation side of the stack.[7][14]
The point is not that every license is equally open. They are not. MIT, Apache 2.0, Modified MIT, Gemma terms, and community licenses create different commercial risk profiles. The point is that the open side is no longer a single underfunded model trying to beat a lab. It is an ecosystem of weights, inference engines, quantizers, adapters, model hubs, agent harnesses, and cloud vendors.
Harvard Business School's working paper argues firms would need to spend 3.5x more on software if OSS did not exist.
The economic precedent is brutal for closed-only narratives. Harvard Business School estimated the demand-side value of widely used open-source software at $8.8 trillion, while the Linux Foundation says organizations contributing upstream see 2-5x benefit-to-cost ratios on average and a modeled 6x ROI for contributing organizations.[9][8]
That is why the phrase "free model" undersells the story. Open infrastructure is not a giveaway. It is a way to move the profit pool upward.
The Strategy: Closed Labs Sell Products, Open Models Become Substrate
Closed labs want to monetize intelligence directly. That is logical. They spent enormous capital training frontier models. They need API usage, enterprise subscriptions, consumer products, and platform gravity. Their ideal world is one where every important AI workflow touches their endpoint.
Open ecosystems monetize differently. They make the primitive abundant, then capture value in hardware, hosting, orchestration, fine-tuning, security, observability, compliance, vertical apps, and services. This is how Red Hat built a business around Linux. It is how cloud providers built empires around open infrastructure. It is how Kubernetes became a standard without one vendor owning every deployment.
The uncomfortable truth for closed labs is that the best model does not always become the most important layer. The most important layer is often the one everyone can standardize around.
The Key Strategic Point
Open models do not have to destroy closed labs. They only have to make the default infrastructure layer too important to rent blindly. Once that happens, the profit moves from owning the model to operating, securing, optimizing, and specializing the stack around it.
This is also why DeepSWE matters even though the closed rows still lead. A benchmark like DeepSWE gives buyers a way to see whether an open model is good enough for a class of work. That is different from asking whether it is the smartest model in the world. Infrastructure buyers do not need theological certainty. They need measured tradeoffs.
If GLM-5.2 is 43.8 percent at $3.92 today, the question is not whether it beats Claude Fable 5 today. It does not. The question is whether the next two years of open model compounding make enough internal workloads routable away from closed APIs that closed providers lose pricing power.
That is the Linux moment.
The Verdict: History Favors The Layer That Compounds
Open source does not win every application. It wins the layer the market needs to share.
The desktop did not become Linux. The server did. Premium phones did not become open in profit share. Android won unit distribution. Databases did not all become Postgres. But Postgres became an obvious default for serious new software. Kubernetes did not make infrastructure simple. It made it portable enough that enterprises could coordinate around it.
Foundation models are starting to face the same split. Closed labs may own the premium frontier. They may keep the best consumer assistants, the hardest reasoning tasks, and the highest-margin managed AI products. That is a real business.
But open models are coming for the ground underneath it. They are coming for the deployment layer, the private workflow layer, the cheap repeated-call layer, the local-device layer, the sovereign infrastructure layer, and the research layer. The market does not need one open model to beat every closed model. It needs open models to become useful enough that every serious buyer has a credible exit path.
What To Watch Next
Watch cost-adjusted agent benchmarks, not only top-line frontier leaderboards. A lower score can still move the market if the cost and control profile changes routing decisions.
Track license quality. MIT and Apache 2.0 models have a different enterprise meaning than open-weight models with heavier commercial restrictions.
Watch inference stacks as closely as model cards. vLLM, SGLang, TensorRT, llama.cpp, quantization, and Kubernetes deployment patterns are where the infrastructure market forms.
Expect closed labs to keep winning premium tasks while open models absorb the boring, repeated, high-volume infrastructure calls around them.
Do not confuse open source with operational simplicity. The winning open providers will be the ones that make governance, observability, security, and deployment boring.
The real story isn't that open models have already won. It is that the primitive is escaping. Closed labs may own the frontier. Open source is trying to own the ground underneath it. In infrastructure markets, that is usually the side history favors.
Sources & References
Key sources and references used in this article
| # | Source | Outlet | Date | Key Takeaway |
|---|---|---|---|---|
| 1 | DeepSWE v1.1 live leaderboard JSON | DataCurve | June 20, 2026 | Provides live v1.1 pass@1, confidence intervals, costs, output tokens, and agent steps across DeepSWE configurations. |
| 2 | DeepSWE benchmark repository | GitHub | 2026 | Defines DeepSWE as 113 original long-horizon software engineering tasks across TypeScript, Go, Python, JavaScript, and Rust. |
| 3 | GLM-5.2 model card | Hugging Face | 2026 | Lists MIT licensing, 1M context, local serving support, and model-card benchmark results including SWE-bench Pro and DeepSWE. |
| 4 | Kimi K2.7 Code model card | Hugging Face | 2026 | Describes Kimi K2.7 Code as a coding-focused MoE model with 1T total parameters, 32B active parameters, 256K context, and Modified MIT weights. |
| 5 | Qwen3-235B-A22B-Thinking-2507 model card | Hugging Face | 2025 | Documents Apache 2.0 licensing, 235B total parameters, 22B active parameters, 262K native context, and LiveCodeBench v6 results. |
| 6 | Mistral 3 announcement | Mistral AI | 2026 | Frames Mistral's open-weight stack around enterprise deployment, Apache licensing, and hardware-aware inference. |
| 7 | Gemma 4 model card | Google AI for Developers | 2026 | Positions Gemma 4 as open weights across multimodal and local development use cases. |
| 8 | ROI for Open Source Software Contribution | Linux Foundation Research | 2026 | Finds reported 2-5x benefit-to-cost ratios for OSS contributions and a modeled 6x ROI for contributing organizations. |
| 9 | The Value of Open Source Software | Harvard Business School Manuel Hoffmann, Frank Nagle, Yanuo Zhou | 2024 | Estimates $8.8 trillion in demand-side value from widely used OSS and says firms would spend 3.5x more on software without OSS. |
| 10 | The 2026 State of Open Source Report | Open Source Initiative | April 28, 2026 | Reports that 55 percent of respondents cite avoiding vendor lock-in as a driver of open source adoption. |
| 11 | Kubernetes Established as the De Facto Operating System for AI | CNCF | January 20, 2026 | Says 82 percent of container users run Kubernetes in production and 66 percent of organizations hosting generative AI models use Kubernetes for inference. |
| 12 | IBM to Acquire Red Hat for $34 Billion | Red Hat | October 28, 2018 | Shows IBM buying into enterprise open source and explicitly tying the acquisition to Linux, containers, Kubernetes, and hybrid cloud portability. |
| 13 | Linux Runs All of the World's Fastest Supercomputers | Linux Foundation | November 20, 2017 | Reports that Linux powered every one of the TOP500 fastest supercomputers, a useful precedent for open infrastructure compounding. |
| 14 | DiffusionGemma 26B A4B model card | Hugging Face | 2026 | Documents DiffusionGemma's 25.2B total parameters, 3.8B active parameters, 256K context, and low-batch throughput claims. |
Last updated: June 22, 2026